

Ijraset Journal For Research in Applied Science and Engineering Technology
Harvestify - Crop Disease Detection and Fertilizer Suggestion using CNN
Authors: Sachin Adulkar, Vivek Pawar, Aniket Choudhari, Shubham Kothekar, Shruti Agrawal
DOI Link: https://doi.org/10.22214/ijraset.2023.50924
Certificate: View Certificate
Abstract
Farmers in many parts of India are having trouble growing crops because of the climate and soil. There could be no genuine assistant available to assist them with encouraging the right sorts of plants using current advancement. Due to illiteracy, farmers may not be able to benefit from advances in agricultural science and continue using human methods. This makes it difficult to achieve the desired yield. For instance, improper fertilization or unintentional rainfall patterns may be the cause of crop failure. In such circumstances, picking crops that are suitable for the soil\'s current conditions and the anticipated rainfall during planting would be the best course of action. Thus, we are presenting an information mining-based \"Soil-Based Profile Profiling Framework.\" In light of the rancher\'s region\'s precipitation and soil input boundaries (NPK and pH), we provide a list of possible yields. Additionally, it suggests fertilizer that can be utilized to increase crop yields and enhance the soil\'s quality. The growing problem of crop failure is the focus of this desktop application.
Introduction
I. INTRODUCTION
In India, 118.6 million farmers rely on agriculture for their livelihood, according to the 2011 census. Understanding the soil conditions, when and where to apply compost, taking into account rainfall, maintaining crop quality, and understanding how various factors operate differently in different parts of the same field are some of the numerous issues that farmers have had to deal with in the past. like while furrowing While settling on significant horticultural choices that might be challenging to carry out all alone or on occasion, various variables and measurements should be considered. This program will provide a solution for agriculture that can assist farmers in increasing their overall productivity by monitoring the agricultural field. Rainfall reserves and soil boundaries, two examples of online weather data, can assist in determining which plants should be planted in a given location. This function introduces a desktop application that predicts the most profitable yields in the current climate and soil conditions using data analysis techniques.
The program will integrate environment and capacity office information. The most significant plants were anticipated in light of the ongoing normal circumstances utilizing an AI calculation. As a result, the farmer can cultivate a wide range of crops. Along these lines, the task encourages a system by solidifying data from various sources, data assessment, and deciding examination, getting to the powerful yield creation and growing the net incomes of farmers, helping them long term. For a fruitful gather, the rancher should deal with the dirt. In order to maximize a harvest's yield and choose the best compost, growers should be aware of the soil's macro and micronutrient content. One significant part of development is soil investigation. Most of individuals come up short on information important to appropriately and decisively plant crops. By analyzing parameters like Sodium (N), Potassium (K), and Phosphorus (P), as well as the pH value of the soil, the region, and the amount of rainfall, our project thus determines which soil-based plants are suitable. mentioned earlier.
A. Proposed Solution
A desktop application that takes in values for nutrients like ph, N, P, and K was our idea. and determines output values for the crops that can produce at that fertility level with fewer nutrients and the soil's fertility level. The majority of Indian ranchers are unfamiliar with the level of ripeness of their soil.
As a result, he has no idea which crops to grow in that soil. Therefore, our system is most beneficial to farmers who are unaware of the fertility level of their soil and the crops they must grow there. We utilized readily available datasets of crop and nutrient values to implement this system. This database was trained with SVM. When the user enters an input, we check our final output after processing the test data and comparing it with the trained dataset using the SVM algorithm.
II. LITERATURE SURVEY
More and more research is being done in the agricultural field right now. Find out what's wrong with Indian agriculture and come up with new ways to help farmers. The suggestions for which yield to develop in view of the dirt's nourishment worth and weather patterns are the essential focal point of the papers [1], [2], and [5]. The author of this paper starts with the fundamentals of smart farming and gradually builds a model to help farmers grow crops that work with the soil and weather. For crop recommendation, this paper makes use of the Machine Learning algorithms SVM, Decision tree, KNN, and ensembles. The conclusion is that the ensembles model and the crop recommendation model work best together [6]. In order to predict which fertilizer will work best for the chosen crop, the author of the paper "Improved Segmentation Approach for Plant Disease Detection" [4] employs a strategy in which he tries a variety of different machine learning models based on micro and macronutrients like nitrogen, phosphorus, pH level, and rain value in millimeters. The performance matrix of the classification algorithm is contrasted in terms of accuracy and execution time. Diseases in a variety of plant leaves can be identified using image processing techniques: A Survey" paper [3] depicts plant infection discovery through a variety of approaches and yield enhancement efforts in striking detail. Using the most recent approach to neural networks, the author has attempted to resolve this issue. This review discusses the requirements and arrangement required to foster a displaying structure for savvy horticulture in the paper "Savvy Cultivating Expectation Utilizing Machine Learning" [7]. It delves into the fundamentals of smart agriculture. The authors begin with the fundamentals before developing a model to support smart agriculture. Using PA principles, this model uses small, open fields to reduce variability at the farmer and crop levels. The model's overall goal is to provide immediate advice to even the smallest farmers at the level of their lowest crop plot using the most readily available technologies like SMS and email. Deep Learning in Computer Vision With the creation of the ImageNet [3] dataset and the ILSVRC [4] challenge, deep learning in computer vision has seen significant advancements. This model was developed for the circumstances in Kerala, where the typical maintenance size is entirely A. For pre-training deep learning models, ImageNet is a popular dataset. At the moment, this is the most common way to deal with computer vision issues when there isn't enough data. ImageNet aims to fill the majority of WordNet's 80,000 synsets with 500–1000 clear, high-resolution images on average [5]. Since their inception, numerous deep convolutional neural networks have been constructed to meet the challenge. Alex Net [6] only has five convolutional layers, whereas the VGG [7] network has 19 arXiv:2204.11340v1 [cs]. LG] layers on April 24, 2022. With the introduction of ResNet [8], the Vanishing/Exploding gradient issue was resolved by utilizing residual connections. Mobile Net [9] takes into account the limited resources and is designed for mobile and embedded vision applications. CNNs can be structurally scaled up using an approach known as Efficient Net [10] that makes use of a highly efficient compound coefficient. B. Plant Disease Detection Plant disease detection is a very active area of research. Over the years, a number of different approaches have been proposed, the most recent of which makes use of deep learning techniques. In [1] for instance, conventional picture handling procedures for example, commotion evacuation, district trimming, picture division utilizing limit recognition and Otsu thresholding were utilized. An Artificial Neural Network was used to extract color, texture, and morphology features.
On the Plant Village dataset, the accuracy of the paper [2]'s use of Alex Net and Google Net—both with and without transfer learning—was 99.35 percent. They also test on scraped data from Bing and Google Search and display activations. An excellent review of over a hundred papers that use Deep Learning to identify and classify plant diseases can be found in Reference [13]. They bring up that a larger part of the papers use Plant Village dataset for their assignment, and convey ImageNetbased pre-prepared models (VGG, ResNet, Origin, Dense Net, and so on.) as their models' foundations.
They also talk about heatmaps, saliency maps, feature maps, activation visualization, segmentation maps, and other visualization methods that were used for this task. On an augmented version of the Plant Village dataset with 87K images, the authors use VGG, ResNet, and Inception-V3 in [2].
They come to the conclusion that VGG is the most suitable for their settings. From 2014 to 2020, several papers classified and detecting plant diseases and pests are examined in another review paper [14]. They also discuss the deep learning theory, methods for classifying after selecting a region of interest, and other topics. Reference [15] talks about different old style machine learning and profound learning methods utilized in location of plant sicknesses. They also go into detail about how, despite the fact that there are a number of online and mobile applications for this purpose, only a small number of them are accessible to the general public online. In addition, they point out that these applications fail to generalize well to real-world images with numerous leaves and extremely diverse backgrounds.
The outcomes of four well-known deep learning models are examined in Reference [16]. VGG-16, ResNet-50, InceptionV4, DenseNet-121 on the Plant Village datasets. 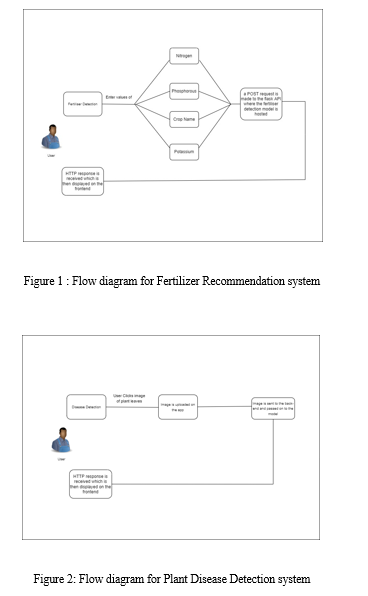
Crop Recommendation In [17], the authors employ support vector machines, artificial neural networks, random forests, and other similar techniques. and conclude that in crop recommendation, random forests are the most effective for their dataset. They likewise make a versatile application framework which takes in area information utilizing GPS and predicts the harvest yield for guaranteed crop, as well as suggesting crops in view of region and soil quality as info. In a similar vein, crop recommendation in [18] is made through majority voting on a group of CHAID, Naive Bayes, K-NN, and Random Trees.
Manure Proposal A ton of assessment has been done in compost idea what's more, a larger piece of them [19]-[22] use the N, P, K, pH potential gains of soil at times besides with significance, temperature, environment, region, precipitation. The most common method is rule-based classification, but some [19] also use K-Means and Random Forests to suggest clustering based on fertilizer date. Interpretability in Profound Learning A clear interpretability technique that utilizes a nearby straight relapse proxy as the first model is the LIME [23] methodology. The predictions made by the original model on images with masks are used to train the linear model. The comparing loads of the picture portions determine the scores. Positive and higher-scoring fragments contribute significantly to the anticipated class, whereas lower-scoring fragments undermine the model's certainty. By using the average of gradients at the last convolutional layer of a CNN-based model and performing a linear combination, the Grad CAM [24] determines the positive influence regions for a particular class. This provides a rough heatmap of important regions for making predictions.
II. METHODOLOGY
The sections that follow go into great detail about our application's implementation, dataset, and training data, as well as the machine learning that was used in our experiments. To begin, we demonstrate the user interface design of our application by employing flowcharts and block diagrams. After that, we move on to our AI tests, where we show off the various models we use and other trial nuances. The nested subsections that separate the two sections are recommendations for fertilizer, plant disease detection, and crop recommendations. The machine learning section provides an explanation of how we use LIME for interpretation, while the application section provides a description of the news feed implementation.
A. The Application
- The Recommendation for Fertilizer: Along with the crop name, the user must enter the nitrogen, phosphorus, and potassium values. To access the flask API, a POST request is made. The hosting location for the fertilizer recommendation classifier is here. The front-end receives an HTTP response and provides the user with a fertilizer recommendation.
- Disease Discovery: In disease detection, the user must either directly upload an image or click on it. The model processes the image after it is sent to the back-end. An HTTP response is sent to the front-end after the image has been processed. The plant's cures for the disease are given to the user. Fig. 2 depicts the same's flow diagram.
The Recommended Crop: A post request to the flask API is made after the values of nitrogen, phosphorus, and potassium are entered. After the model runs a HTTP reaction is shipped off the front-end which tells the best yield a rancher can fill in the dirt to get the best out of the land. Fig. The same's flo diagram can be seen in Figure 3.

4. Disease Website: The disease portal provides a comprehensive overview of various plant diseases and the various products that can be purchased to treat them.

5. Evaluation of Interpretability: The user's plant leaf image is sent to a deployed API, where the LIME computation is performed on a droplet server hosted on Digital Ocean. The resulting image is sent as a URI, and it is displayed on the front end.
B. A Crop Machine Learning Proposal: The Set's Description
This dataset, taken from Kaggle 1, is somewhat basic and contains few but important elements, not at all like the confused highlights influencing harvest yield. It has seven specific highlights, specifically N: The ratio of the nitrogen content of the soil, P: K: Temperature, phosphorus and potassium content of the soil in relation to one another: Celsius temperature and the amount of humidity: percent of relative mugginess, ph.: precipitation, the dirt's ph. value: mm of precipitation. The task is to expect the sort of reap using these 7 components. There are 2200 examples and 22 class names altogether, including the accompanying: Rice, coffee, muskmelon, and other foods The fact that each class has 100 samples demonstrates that the dataset is perfectly balanced and does not require any special imbalance handling techniques.Approach: Cross-validation on these five folds is carried out on the dataset, which is divided into folds. Six models are used to evaluate performance:
- Decision Tree with a maximum depth of 5 and entropy as the criterion
- The naive Bayes
- A SVM with an input scaling of 0 to 1, a degree 3 polynomial kernel, and the L2 regularization parameter C=3
XGBoost can be found at Except for XGBoost, which is derived from the xgboost library, all of the models are implemented with the sklearn library. For the purposes of our training, the parameters that aren't mentioned are set to default. For the purpose of the application, we choose the model with the highest performance and use it for inference.
Disease Recognition: Dataset Depiction: We look at the PlantVillage dataset for leaf disease detection. In particular, we make use of an enhanced version of the PlantVillage dataset that is available on Kaggle2. There are 87,000 RGB examples of both healthy and diseased crops in the dataset, each with a spread of 38 class labels. There are 14 crops included, and there are a total of 26 distinct diseases. Overall, each class contains 1850 picture tests with a standard deviation Of 104. The ratio of training to validation in the dataset has been divided into 80:20. With only a picture of the plant leaf, we try to predict the crop-disease pair. We resize the images to 224 x 224 pixels and reduce their size by 255 times. Figure depicts a sample batch from the PlantVillage dataset. We perform both the model streamlining and expectations on these downscaled pictures. Approach: We employ three ImageNet-pretrained models for our experiments: VGG-16, ResNet-50, and EfficientNetB0. The ImageNet dataset performance of these models is influenced by their sizes, parameter counts, and performance. It has been shown that these pre-prepared models perform better compared to a model prepared without any preparation on the PlantVillage dataset. With an initial learning rate of 2e-5, beta values of (0.9, 0.999), and an epsilon of 1e-08, we employ the Adam optimization method with categorical cross-entropy loss during training. A low learning rate is utilized to forestall the difference of the model and to safeguard crude picture channels recognized during pre-preparing. During training, a batch size of 32 and a number of epochs of 25 are utilized. Moreover, we likewise utilize early pausing and model checkpointing in view of the approval misfortune, which gives us During the training, we also record the model's accuracy. These models' capabilities may be enhanced
When working with a dataset of images, the graphics processing unit (GPU) should be used rather than the central processing unit (CPU). This is because GPUs permit multiple parallel computations, which makes training and inference faster. We utilize the free GPUs given by Kaggle and Google Collab for our analyses. Ultimately, we utilize the LIME technique to comprehend the forecasts made by our best model. For this, we utilize 1000 examples in the LIME strategy from the lime bundle, and we really take a look at the emphatically weighted sections towards the anticipated class. After that, we plot the top ten crucial sections on the image and present them to the application. However, the application only uses 249 samples because of computation limitations. LIME provides better explanations with larger numbers of samples.
A Recommendation for Fertilizer: Dataset Depiction: We use a custom dataset3 with five features for fertilizer recommendation: crop, nitrogen, phosphorus, potassium, pH, and soil moisture. There are 22 crops, including coffee beans, rice, and maize. with their ideal values for N, P, and K. The data set shows how much N, P, and K should be in the soil for the crop to grow the most effectively. The farmer should use a fertilizer based on the N, P, or K value that is lacking.
Approach: To select the most effective fertilizer for a plant, we employed rule-based classification, a classification scheme that makes use of IF-THEN rules for class prediction. A fertilizer may be required depending on how far a plant is from its ideal N, P, or K value. For our motivations, we have 6 sorts of manure suggestions right now, in view of whether the N/P/K qualities are high or low.
IV. RESULTS AND DISCUSSION
A. Crop Recommendation
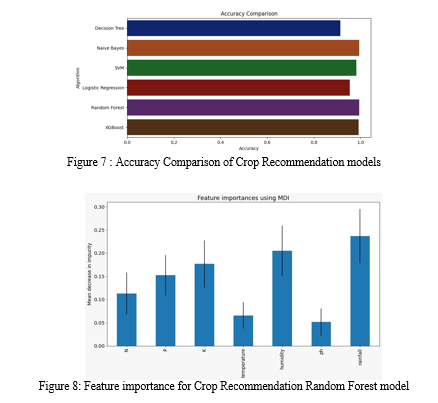
T he Fig. and the results of our crop recommendation experiments are shown in Table I. These scores are also shown on a bar graph by 5 for easy examination. We can see that the XGBoost model performs the best, followed by the Random Forest and Naive Bayes models. Supporting (Random Forest) and packing (XGBoost) models typically outperform non-troupe strategies in terms of performance and sum. Due to the fact that it has a cross-validation accuracy of 0.995, the Random Forest model was chosen for our application. This is because we are able to easily comprehend the features' feature importances, which indicate how crucial the features are to our classification. The Picture The element significance that we compute utilizing the Irregular Timberland model is displayed in Figure 6. We track down that the main figure deciding the kind of harvest is precipitation. The general water content, trailed by the nature of the dirt, is extremely critical. Consequently, by employing this model, we can also comprehend which features are typically essential to our crop proposal model. Humidity comes in second, followed by K, P, and Consequently, utilizing this model, we can likewise comprehend which highlights are generally speaking critical to our model for crop proposal.
B. Crop Infection Identification
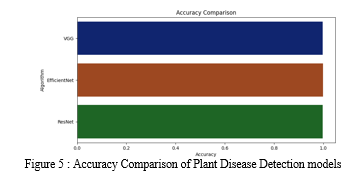
We reason that the Efficient Net model performs the best of all since VGG, ResNet, and Efficient Net received the highest approval scores. Fig. By contrasting the accuracy of the three models, 7 demonstrates this. In Fig, we likewise show the precision and misfortune bends for the three models. The accuracy curves demonstrate that Efficient Net achieves the highest score quickly in comparison to the other two models. The Productive Net is a class of a couple of front line convolutional mind network based models which are made including a coordinated system for scaling cerebrum associations. Out of all the CNN-based models that have been developed previously, they have the highest score after being trained on the ImageNet dataset. As a result, in order to perform leaf picture classification, we select the Efficient Net model and incorporate it into our application.

C. LIME Interpretability Evaluation
The LIME explanation for the samples is then compiled using this Efficient Net model. LIME generates an image for each sample that highlights the relevant important segments. What the model is focusing on in the image to make its prediction is revealed by this. In the Fig. 9 and Fig. 10, which indicates that the regions the model examines are consistent with the diseased portions of the leaf, has diseased regions marked as positive segments. We anticipate more accurate and fine-grained explanations with more samples. Furthermore, we intend to expand the picture size and utilize better division calculations to have the option to produce better and all the more fine-grained clarifications in a future work. This lets you know if the model looks at the right diseased areas and what kinds of images can be added to the training dataset to make it better at generalizing.

Conclusion
The \"Farmer\'s Assistant\" is a user-friendly web application system based on machine learning and web scraping that we propose in this paper. We can give a few elements our framework, including crop illness location utilizing an Effective Net model on leaf pictures, compost suggestion utilizing a standard based grouping framework, and harvest proposal utilizing the Irregular Timberland calculation. By using our user interface, the user can quickly get their results by filling out forms. Additionally, we utilize the LIME interpretability strategy to make sense of our forecasts on the sickness identification picture. We might be able to improve datasets and models that make use of this information and understand why our model states what it does. Even though our application runs very smoothly, there are many ways we can make it better. First, we can suggest fertilizer and crop recommendations that can be found on popular online shopping sites. Users may also be able to make direct purchases of fertilizers and crops through our app. Another way fertilizer recommendation can be improved is if we can find data on the various brands and products that are available based on the N, P, and K values. We currently only provide six types of proposals; however, in the future, we should be able to use sophisticated AI frameworks to provide better suggestions. Following that, we come to the realization that the dataset we used to classify diseases is incomplete. This suggests that only images belonging to classes that our model already understands perform well. It will not be able to correctly classify data that is outside the domain. There are two options for dealing with this problem in the future. Finding extra datasets with different harvests or potentially infections at comparable scales or producing and scaling those datasets utilizing generative demonstrating to add to our preparation set is one choice. As a result, our model\'s ability to generalize will improve. The next option is for customers to be able to add their own images by entering our web application and commenting on the actual images. Also, it has been exhibited that LIME clarifications all by themselves are not generally reliable because of the way that they just give nearby data about a model and don\'t resolve the worldwide issues the model spotlights on. Grad CAM and Integrated Gradients are two additional methods that we can use as a result. or additional training techniques like LIME\'s sparse-linear layers to better explain our model predictions Last but not least, we plan to offer diseased dataset segmentation on a more fine level. Due to a lack of such data, this is currently impossible. However, we are able to incorporate a segmentation annotation tool into our application to allow users to help us fill the void. Additionally, with the assistance of a few unsupervised algorithms, we are able to identify the image\'s diseased regions. In the upcoming work, we intend to include these highlights and fill in the gaps.
References
[1] S. D. Khirade and A. B. Patil, \"Plant Disease Detection Using Image Processing,\" 2015 International Conference on Computing Community Control and Automation, pages 768-771, doi: IC-CUBEA.2015.153, 10.1109 [2] \"Image-based Plant Diseases Detection Using Deep Learning,\" by A. V. Panchal, S. C. Patel, K. Bagya lakshmi, P. Kumar, I. Raza Khan, and M. Soni, Materials Today: Proceedings, 2021, https://doi.org/10.1016/j.matpr.2021.07.281, ISSN 2214-7853. [3] \"ImageNet:\" by J. Deng, W. Dong, R. Socher, L.-J. Li, Kai Li, and Li Fei-Fei A huge scope various leveled picture information base\", 2009 IEEE Meeting on PC Vision and Example Acknowledgment, 2009, pp. 248-255, doi: 10.1109/CVPR.2009.5206848. [4] Russakovskyetal., \" ImageNet Large Scale Visual Recognition Challenge,” International Journal of Computer Vision, 115(3), pp. 211–252, 2015. https://doi.org/10.1007/s11263-015-0816-y. [5] George A. Mill operator, \"WordNet: A Lexical Database for English,” ACM Communications, Vol. 38, No. 11: 39-41. [6] \"ImageNet Classification with Deep Convolutional Neural Networks,\" in Advances in Neural Information Processing Systems 25 (NIPS 2012), by A. Krizhevsky, I. Sutskever, and G. E. Hinton. [7] “Very Deep Convolutional Networks for Large-Scale Image Recognition,” K. Simonyan and A. Zisserman, 2014, arXiv 1409.1556. [8] \"Deep Residual Learning for Image Recognition,\" 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pp. 770-778, doi: 10.1109/CVPR.2016.90. [9] Howard and others, MobileNets: Productive Convolutional Brain Organizations for Versatile Vision Applications\", 2017, arXiv 1512.03385 [10] M. Tan, Q. Le,(2019), \"EfficientNet: Reexamining Model Scaling for Convolutional Brain Organizations\", Procedures of the 36th Global Meeting on AI, in Procedures of AI Exploration, 2019, 97:6105-6114. [11] \"An open access repository of images on plant health to enable the development of mobile disease diagnostics,\" by D. P. Hughes and M. Salathe, 2015, arXiv 1511.08060. [12] SP Mohanty, DP Hughes DP, M. Salath e\', \"Involving Profound Learning for Picture Based Plant Infection Recognition\", Front. Plant Phys. 2016, 7:1419. doi: 10.3389/fpls.2016.01419. [13] \"Plant Disease Detection and Classification by Deep Learning,\" in Plants, 2019, 8, no. 11: 468. https://doi.org/10.3390/plants8110468. [14] \"Plant diseases and pests detection based on deep learning:\" by J. Liu and X. Wang a review,” Plant Methods 17, 22 https://doi.org/10.1186/s13007-021-00722-9. [15] \"Image-Based Detection of Plant Diseases:\" by R. U. Khan, K. Khan, W. Albattah, and A. M. Qamar. From Classical Machine Learning to the Journey of Deep Learning,” in Wireless Communications and Mobile Computing, vol. 2021, Article ID 5541859, 13 pages, 2021. https://doi.org/10.1155/2021/5541859. [16] Computers and Electronics in Agriculture, Volume 161, 2019, Pages 272-279, ISSN 0168-1699, https://doi.org/10.1016/j.compag.2018.03.032, “A comparative study of fine-tuning deep learning models for plant disease identification,” by E. C. Too, L. Yujian, S. Njuki, and L. Yingchun. [17] S. M. Pande, P. K. Ramesh, A. Anmol, B. R. Aishwarya, K. Hilla, and K. Shaurya, \"Crop Recommender System Using Machine Learning Approach,\" 2021, 5th International Conference on Computing Methodologies and Communication (ICCMC), pages 1066-1071, doi: 10.1109/ICCMC51019.2021.9418351. [18] \"Crop recommendation system for precision agriculture,\" in S. Pudumalar, E. Ramanujam, R. H. Rajashree, C. Kavya, T. Kiruthika, and J. Nisha\'s 2016 Eighth International Conference on Advanced Computing (ICoAC), 2017, pp. 32-36, doi: 10.1109/ICoAC.2017.7951740. [19] \"Design and Implementation of Fertilizer Recommendation System for Farmers,\" by K.S. Subramanian in 2020. [20] A. Pratap, R. Sebastian, N. Joseph, R.K. Eapen, S. Thomas, \"Soil Fertil-ity Examination and Manure Suggestion Framework\", Procedures of In-ternational Gathering on Headways in Processing and The board (ICACM) 2019, Accessible at SSRN: http://dx.doi.org/10.2139/ssrn.3446609 or https://ssrn.com/abstract=3446609 [21] A. Palaniraj, A. S. Balamurugan, R. D. Prasad, and P. Pradeep, \"Crop and Fertilizer Recommendation System using Machine Learning,\" International Research Journal of Engineering and Technology (IRJET) 2021, Volume 08, Issue 04 [22] \"Agro based crop and fertilizer recommendation system using machine learning,\" in European Journal of Molecular & Clinical Medicine, 7, 4, 2020, 2043-2051, by G. Preethi, P. Rathi, S. M. Sanjula, S. D. Lalitha, and B. V. Bindhu. [23] \"Why Should I Trust You?\" by C. Guestrin, S. Singh, and M. T. Ribeiro: In the proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (KDD \'16), the article titled \"Explaining the Predictions of Any Classifier\" appears. New York, NY, USA: Association for Computing Machinery, 2016, pp. 1135–1144. DOI: https://doi.org/10.1145/2939672.2939778. [24] \"Grad-CAM::\" by R. R. Selvaraju, M. Cogswell, A. Das, R. Vedantam, D. Parikh, and D. Batra. Visual Explanations from the Deep Net Using Gradient-Based Localization,” in Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), 618-626, doi: 10.1109/ICCV.2017.74.
Copyright
Copyright © 2023 Sachin Adulkar, Vivek Pawar, Aniket Choudhari, Shubham Kothekar, Shruti Agrawal. This is an open access article distributed under the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.

Download Paper
Paper Id : IJRASET50924
Publish Date : 2023-04-24
ISSN : 2321-9653
Publisher Name : IJRASET
DOI Link : Click Here
 Submit Paper Online
Submit Paper Online